There were three big competitions planned for this week: Challenge24 2015 Electronic Contest, TopCoder SRM 651 and Open Cup 2014-15 Grand Prix of China. However, the first two faced some serious issues, and the Open Cup is yet to happen tomorrow. Given that I've falled a bit behind on the Open Cup rounds, I will keep this week's summary without any news, and continue describing the Open Cup rounds from February.
Last week we discussed a very nice problem from the Grand Prix of Japan: count the number of pairs of strings (s, t) such that the length of s is N, the length of t is M, each character is from an alphabet of size A, and t is a substring of s.
Suppose the string t is fixed. How do we count the number of strings s of given length that contain t? We will count two things: the number an of strings s of each length n between 1 and N that do not contain t, and the number bn of strings s of each length n that contain t, but only as a suffix and not before. First approximation for an is simple: we have to take a string of length n-1 and add one character to it, so we have an=an-1*A. Of course, that formula is not correct because it doesn't take t into account at all. How could t appear in the length-n string, if the first n-1 characters didn't contain t? Well, it must appear at the rightmost position, so the correct formula is an=an-1*A-bn.
 But how do we find bn? Well, the first approximation is also simple: we have to take a string without any appearances of t, and add t in the end: bn=an-M. However, this is also not correct because by adding t in the end, we might've also added some occurrences of t before the end, so we need to subtract something. Well, let's look at the first appearance of t that we added - let's say it ends p (p>0) characters from the end. This can happen only if t has a border (a string that is both its prefix and its suffix) of length M-p - see the picture on the left. And for each string of length n-p that ends with t, there's exactly one way to extend it to a "bad" string of length n. So the correct formula is: bn=an-M-sum(bn-p), where the sum is taken over all positive p such that there's a border of length M-p in t.
But how do we find bn? Well, the first approximation is also simple: we have to take a string without any appearances of t, and add t in the end: bn=an-M. However, this is also not correct because by adding t in the end, we might've also added some occurrences of t before the end, so we need to subtract something. Well, let's look at the first appearance of t that we added - let's say it ends p (p>0) characters from the end. This can happen only if t has a border (a string that is both its prefix and its suffix) of length M-p - see the picture on the left. And for each string of length n-p that ends with t, there's exactly one way to extend it to a "bad" string of length n. So the correct formula is: bn=an-M-sum(bn-p), where the sum is taken over all positive p such that there's a border of length M-p in t.
In other words, it turns out that knowing all border lengths of t is sufficient for finding the number of strings of any given length that contain it. At the same time, not all sets of border lengths are possible, since having even one border implies a lot of equalities between the string characters, and in case we have several, the string quickly converges to having all characters equal, and thus all border lengths at the same time. This idea inspires a reasonably simple backtracking: let's try to build all non-contradictory sets of border lengths for a string of length M by recursively trying to include/not include the longest border (of length M-1), then M-2, and so on. We will bail out from the recursion as soon as we have a contradiction. In order to check if we have one, we will build equivalence classes of characters according to borders that do exist, and check if they imply a border that we've declared as not existing.
This recursion runs almost instantaneously for M=50, and reports that there are only 2249 non-contradictory sets of border lengths. We have almost solved our problem: we can iterate over all possible sets of border lengths, and find the number of strings s that contain a string t with such set of border lengths using the dynamic programming described above. But note that we must also multiply that by the number of such strings t - so we also need to find the number of strings with the given set of border lengths.
The latter, on the surface, is also computed easily: it's simply A to the power of the number of equivalence classes defined by the borders. But as you've probably guessed, this will overcount: here we won't throw out the strings that have some additional borders. But since we have just 2249 different sets of borders, we can fix this by simply subtracting the numbers of strings for all supersets of our set of border lengths, obtaining a dynamic programming approach for counting t's. And that completes the solution!
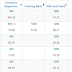
 The next round of the Open Cup, Northern Grand Prix, happened three weeks ago (results, top 5 on the left). Just like the Grand Prix of Japan, this round featured many interesting problems, but I'd like to highlight two. Problem B was also about string borders: one needed to count the k-th lexicographically borderless word of length n (up to 64), where a word is borderless when it has no non-trivial borders. Riding the wave of the solution explained above, I've tried to use the same approach by using inclusion-exclusion principle over sets of possible border lengths - but unfortunately, this approach was a bit too slow for the time limit. Can you see how to solve this problem faster?
The next round of the Open Cup, Northern Grand Prix, happened three weeks ago (results, top 5 on the left). Just like the Grand Prix of Japan, this round featured many interesting problems, but I'd like to highlight two. Problem B was also about string borders: one needed to count the k-th lexicographically borderless word of length n (up to 64), where a word is borderless when it has no non-trivial borders. Riding the wave of the solution explained above, I've tried to use the same approach by using inclusion-exclusion principle over sets of possible border lengths - but unfortunately, this approach was a bit too slow for the time limit. Can you see how to solve this problem faster?
Problem D considered languages defined by deterministic finite automata. More precisely, one needed to define a language containing just the given word, and no other words. When the given word has length n, it's easy to construct an automaton with n+2 states that accepts the given word and only the given word: a chain of n+1 states that have transitions using the characters of the word, the (n+1)-st state being final and all other transitions leading to (n+2)-nd "sink state" which is not final. This problem, however, limited the automata to n+1 states. It's not hard to see that it's impossible to create an automaton with n+1 states that accepts the given word of length n and only that word. Because of that, you were asked two output two automata with at most n+1 states that have the language with just one word in their intersection - in other words, such that both of them accept the given word of length n, and there's no other word such that both of them accept it. Can you figure this one out?
Thanks for reading, and check back next week!
In other words, it turns out that knowing all border lengths of t is sufficient for finding the number of strings of any given length that contain it. At the same time, not all sets of border lengths are possible, since having even one border implies a lot of equalities between the string characters, and in case we have several, the string quickly converges to having all characters equal, and thus all border lengths at the same time. This idea inspires a reasonably simple backtracking: let's try to build all non-contradictory sets of border lengths for a string of length M by recursively trying to include/not include the longest border (of length M-1), then M-2, and so on. We will bail out from the recursion as soon as we have a contradiction. In order to check if we have one, we will build equivalence classes of characters according to borders that do exist, and check if they imply a border that we've declared as not existing.
This recursion runs almost instantaneously for M=50, and reports that there are only 2249 non-contradictory sets of border lengths. We have almost solved our problem: we can iterate over all possible sets of border lengths, and find the number of strings s that contain a string t with such set of border lengths using the dynamic programming described above. But note that we must also multiply that by the number of such strings t - so we also need to find the number of strings with the given set of border lengths.
The latter, on the surface, is also computed easily: it's simply A to the power of the number of equivalence classes defined by the borders. But as you've probably guessed, this will overcount: here we won't throw out the strings that have some additional borders. But since we have just 2249 different sets of borders, we can fix this by simply subtracting the numbers of strings for all supersets of our set of border lengths, obtaining a dynamic programming approach for counting t's. And that completes the solution!
Problem D considered languages defined by deterministic finite automata. More precisely, one needed to define a language containing just the given word, and no other words. When the given word has length n, it's easy to construct an automaton with n+2 states that accepts the given word and only the given word: a chain of n+1 states that have transitions using the characters of the word, the (n+1)-st state being final and all other transitions leading to (n+2)-nd "sink state" which is not final. This problem, however, limited the automata to n+1 states. It's not hard to see that it's impossible to create an automaton with n+1 states that accepts the given word of length n and only that word. Because of that, you were asked two output two automata with at most n+1 states that have the language with just one word in their intersection - in other words, such that both of them accept the given word of length n, and there's no other word such that both of them accept it. Can you figure this one out?
Thanks for reading, and check back next week!





0 komentar:
Post a Comment